
Our site, raywenderlich.com, utilizes a tech stack comprised of multiple Ruby on Rails services to power the raywenderlich.com website experience. This architecture pattern is a useful technique in building websites. It allows you to separate concerns into their own service with the benefit of being able to independently build, scale and deploy them individually. Because of this separation, there may be a need in which your services still need to communicate with each other. One way to achieve this is through a pattern called the publish-subscribe pattern, referred to as pub/sub messaging.
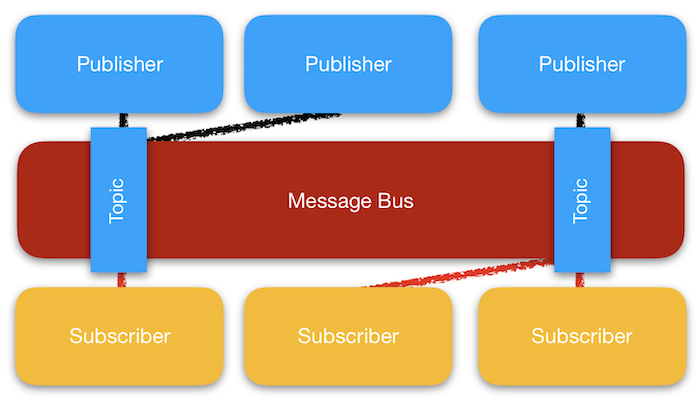
Pub/sub messaging is the act of one service publishing data to a shared service, often called a message bus. A subscriber maintains a connection to this shared message bus, which will eventually receive published messages. In systems with a heavily utilized message bus, it is not uncommon to have multiple publishers publishing to multiple channels to be received by multiple subscribers. Although there are many different implementations available, our site uses Amazon SNS.
Dropped or out of order messages
In the raywenderlich.com tech stack, we have a separate service that manages our store, kerching, and another service that manages our video content, betamax. From a high-level perspective, kerching knows which users have bought which video product. This, in turn, requires betamax to know which user has access to a video when requested.
Previously, the quickest way to move this information was to broadcast a message on the bus when a user had either gained or lost access to a product. Each message was encoded with the user’s ID, the product that changed, and whether or not they had access. The subscriber, betamax, read each message and updated its own internal database of each user’s accessible products.
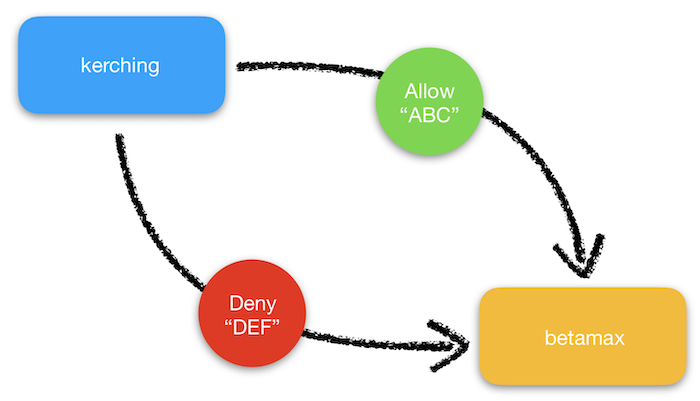
While this worked out well for quite a while, we eventually started to notice issues in which some users were unable to access videos even though they were subscribers.
This lead us to chase down message logs and piece together the state of a user’s access for each message that would alter their permissions. The reason for this was that pub/sub messaging is just not a reliable way to transmit state. In certain implementations, messages can be delivered out of order and are not necessarily guaranteed to arrive. In the case of some subscribers not having access, it was possible that some messages did not successfully arrive. This could have been due to network connectivity issues, deployments or other reasons we have yet to uncover.
The most important thing we wanted to get right was to ensure that our users had the correct access to their videos. With this being our primary goal, we decided to undo any message optimizations and, instead, aim for accuracy.
We achieved this by limiting the amount of information sent in a message to just a simple notification that access had changed. With this notification, betamax now only knows that a user’s access has changed, but still doesn’t know in what way. This required betamax to make an API request to kerching to synchronize all product accesses. This is also known as making your messages idempotent.
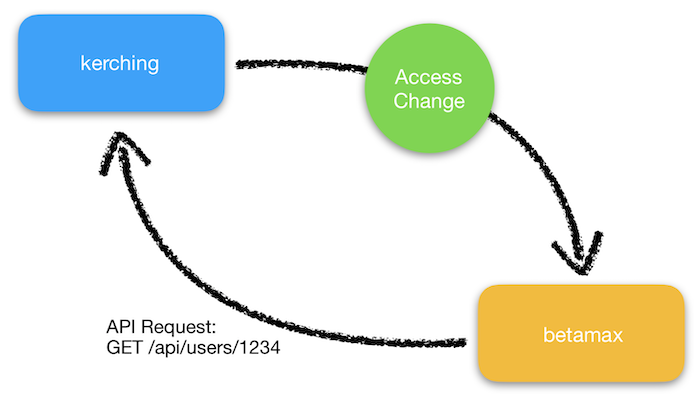
With this new setup, it doesn’t matter what information or in what order betamax receives a message. The end result will always be the same. Fortunately, betamax and kerching have a sizeable amount of traffic that can handle a few more API calls without having to scale unnecessarily. This change not only decreased the amount of issues we received, but also made it far easier to debug when issues did arise.
Defer and delegate further processing
The newest part of our tech stack is our content aggregation service, carolus. This is the main part of the website our visitors see daily.
Now, you are probably begging to know how this site aggregates data from several other sources of information in such a seamless manner? Well, I’m glad you asked.
We built carolus to subscribe to all content changes that happen in the world of raywenderlich.com. As outlined in our CTO Sam Davies’ post, “How Does raywenderlich.com Work?, we have different admin interfaces that generate our content, which all eventually end up in carolus.
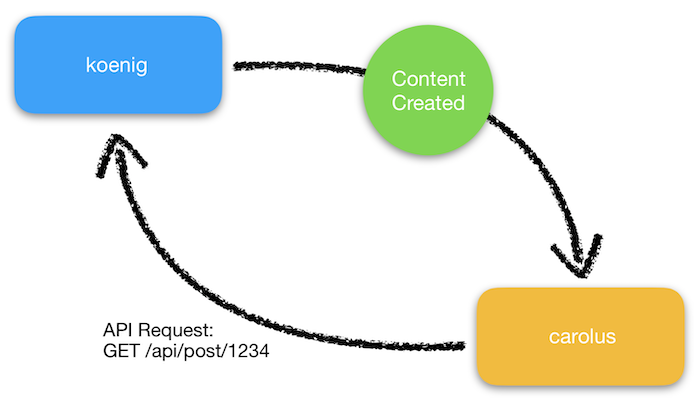
When content is generated for the site, a notification is sent on our message bus with a unique identifier. The service subscriber, carolus, then reads these notifications. The unique identifier has information that tells carolus what admin service generated the content and how to look it up. At this point, carolus can fetch the content using an API request.
Let’s say, for instance, we naively set up our subscription event cycle like this:
It is important to note that carolus currently runs off of two web processes with five threads each. These web processes handle everything from public and admin traffic, and subscriber events. This means that, if our processes are tied up, they will be unable to serve other requests.
Since we live in a service-oriented world, the availability of carolus shouldn’t be dependent on the reliability of external factors, which include other services in our system. If carolus makes an API request to fetch data that takes a really long time, this can be bad. A tied-up thread becomes your bottleneck. Once notifications force carolus to make a really long API requests multiple times, it will start losing the ability to handle traffic, affecting user experience with noticeable slowdowns.
To get around this, we opted to make use of another background processing technique in the form of a queue. In our case, we use Sidekiq, which is backed by Redis. When carolus receives content notifications, the events controller queues up the notification into Redis and returns right away. This frees up a process to handle a new incoming request because now a Sidekiq process makes the API request.
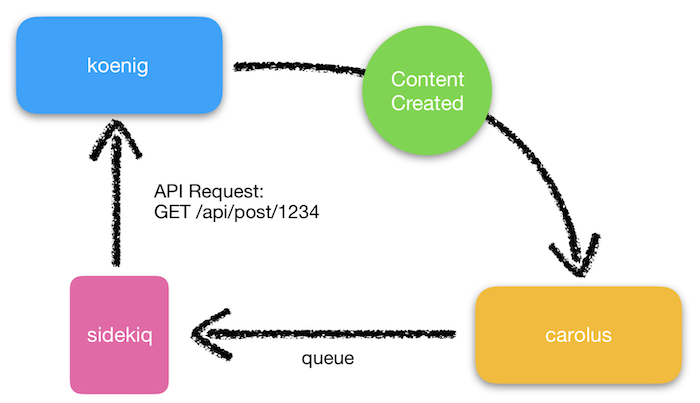
We can now increase the amount of notifications that we can handle, which allows us to serve real users without having to scale horizontally. Another added benefit of this is that we can fine tune how many worker process we need and even scale it based on the load on the queue. This can all be done without affecting carolus’ ability to serve our users.
Working with Amazon SNS has been a great experience in learning about how pub/sub systems work. The two key take aways that I can generalize are as follows:
- Ensure that your messages are idempotent. This makes both the publishing and subscribing implementations simpler, and, in turn, makes debugging issues easier.
- Defer any action or logic away from the processing of messages in your subscribers. Not only will you be able to handle more traffic, but it will also make testing simpler by being more modular.
Implementing a message bus is integral in properly organizing the flow of data in your service-oriented architecture. Just keep in mind that it is not an end-all solution, but it can solve a lot of your problems when used carefully. If you want to learn more about our experiences or just want to chat, feel free to hit me up on Twitter!

Interests: Ruby on Rails, games, and basketball.